From read-only to editable
in one click.
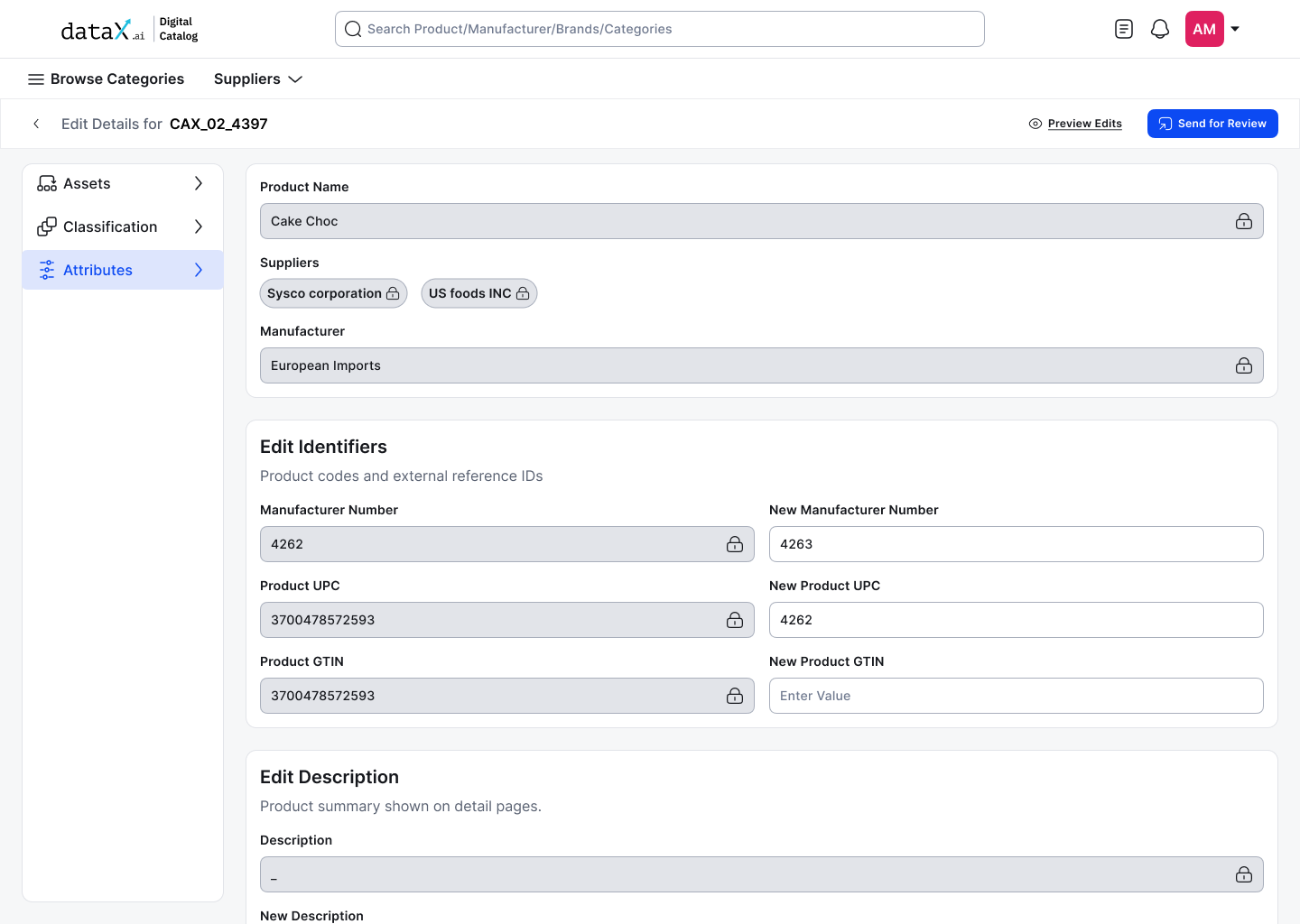
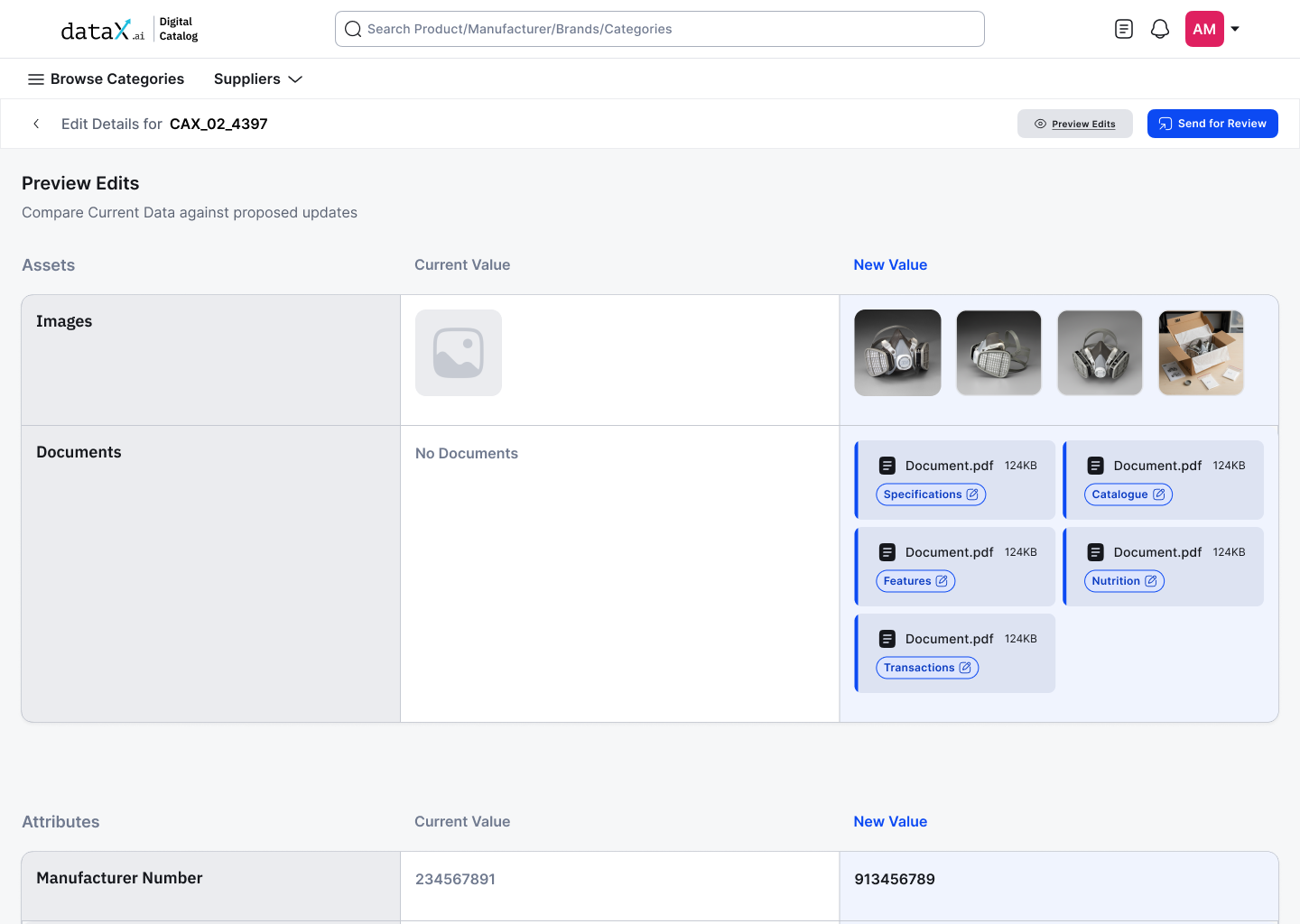
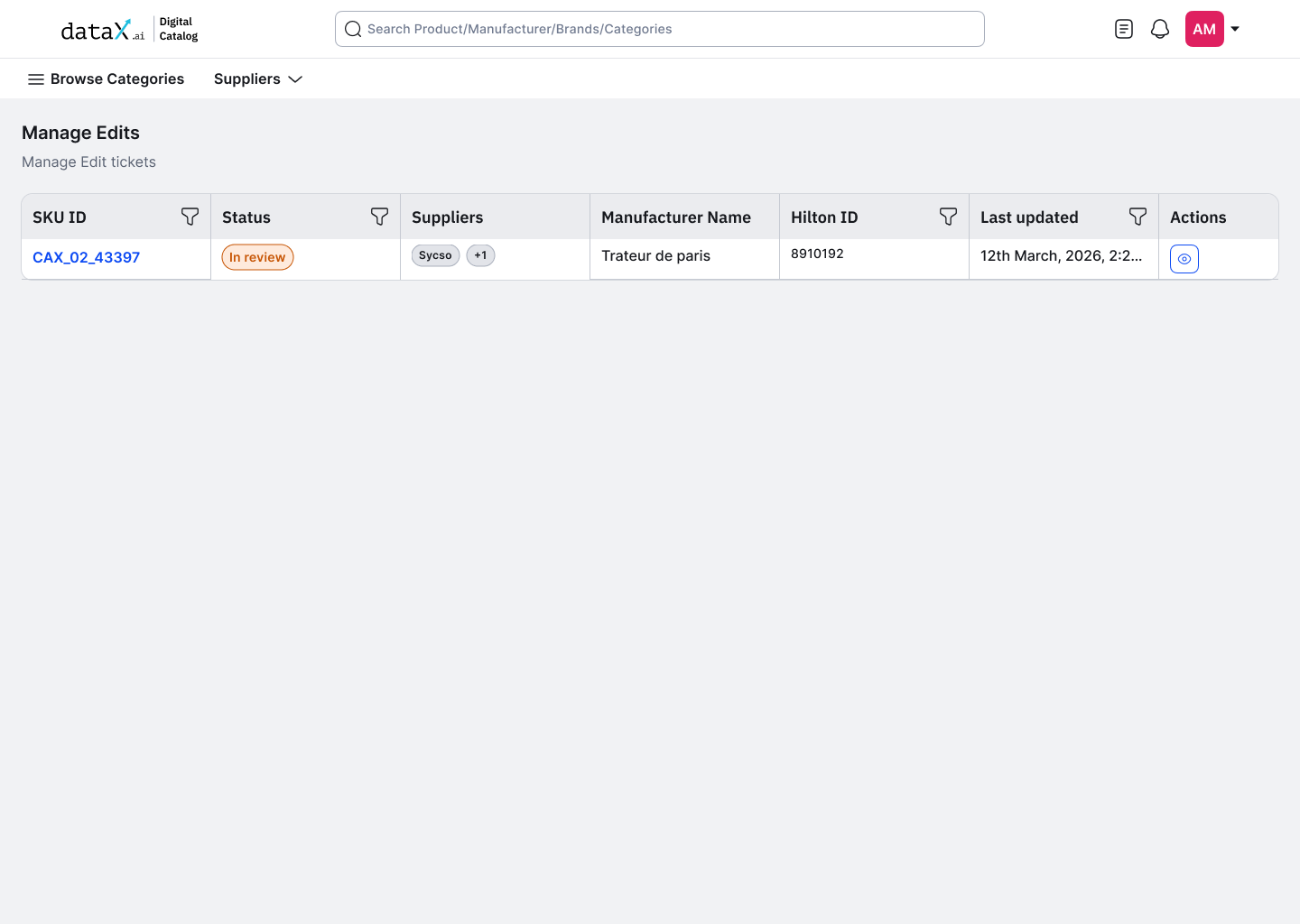
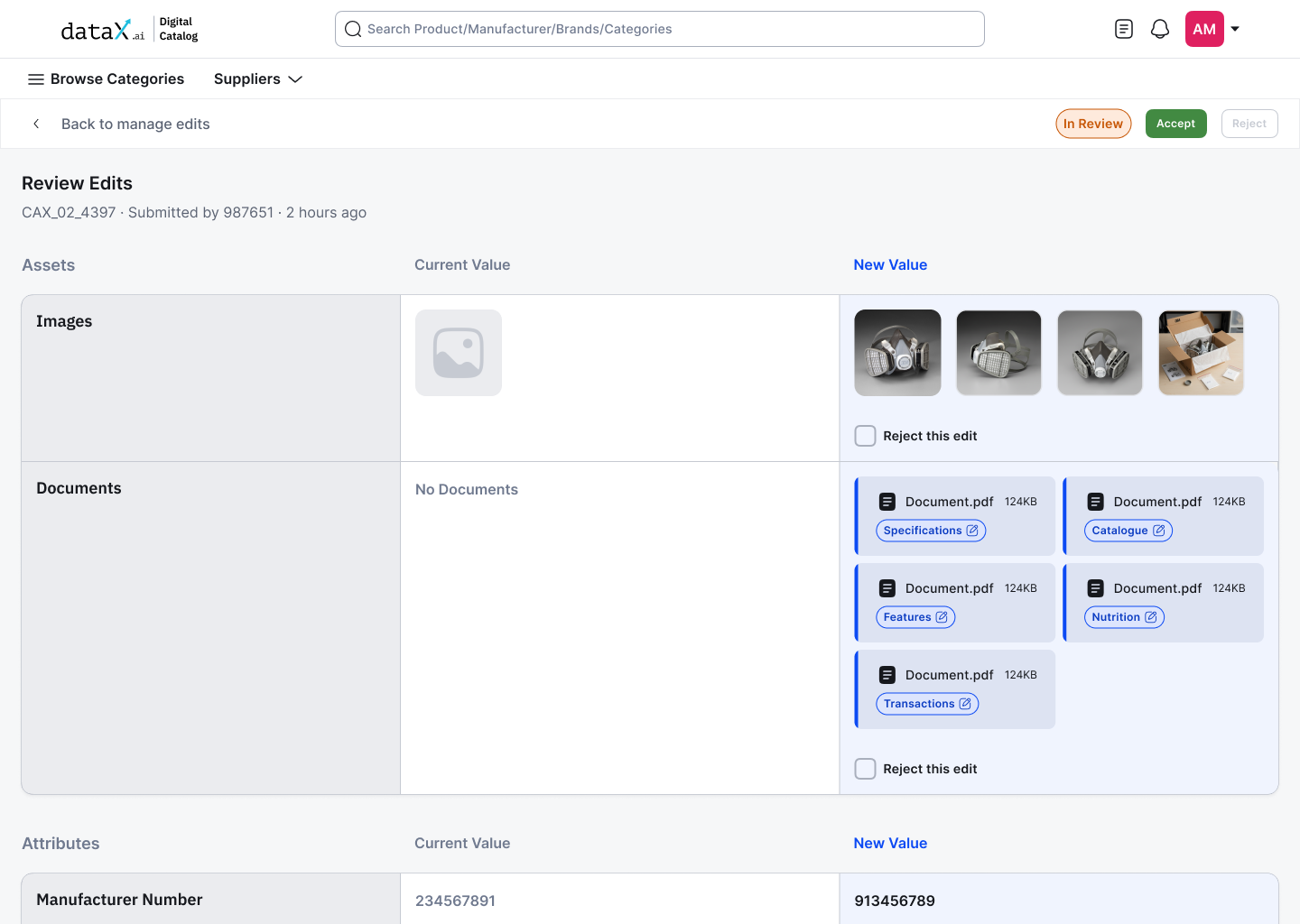
The edit flow begins on the Product Details Page, the same page where incorrect data lives. No navigation to a separate editing interface, no context switch. The edit button lives where the problem is visible.
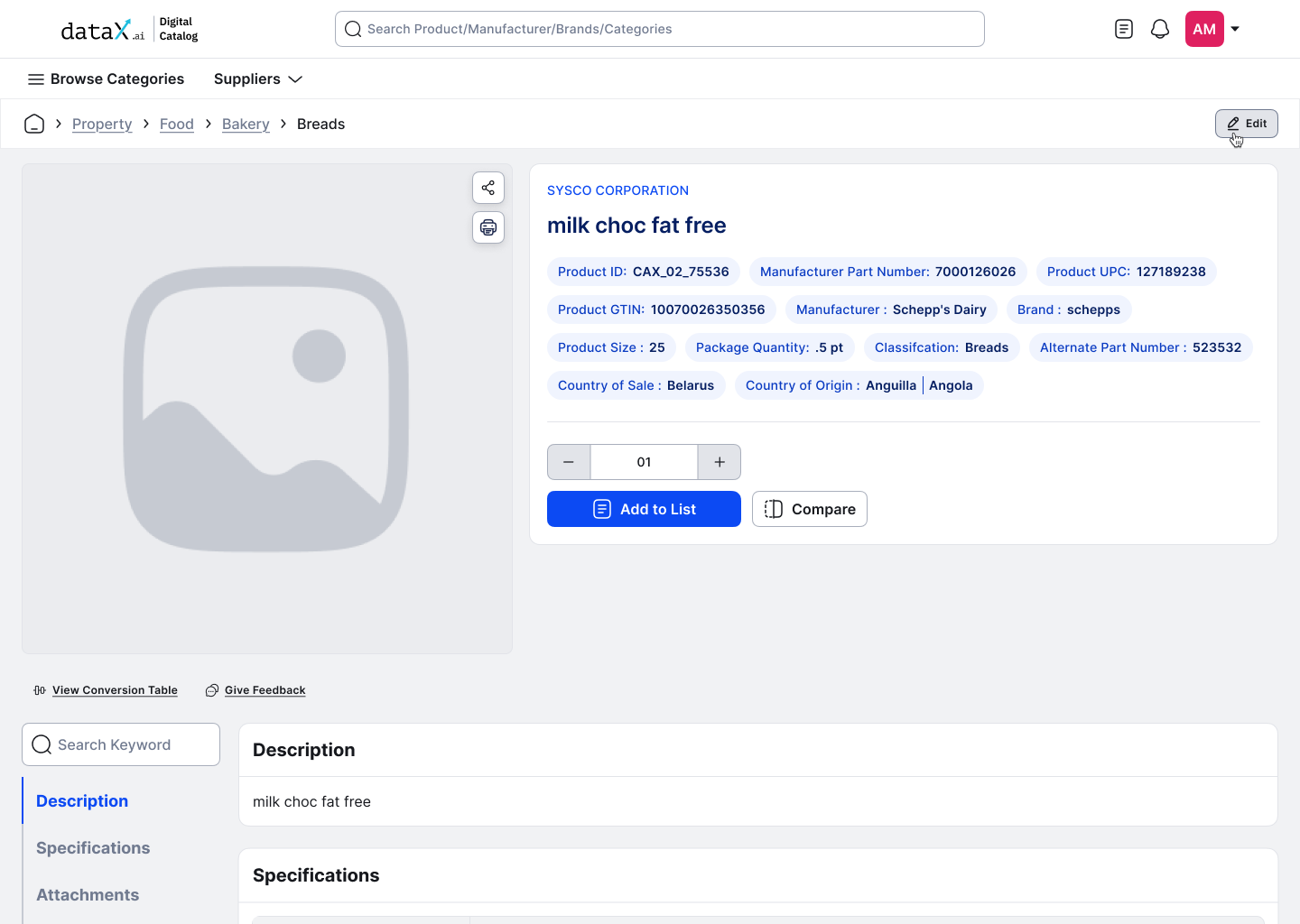
EF-01 · PDP TRIGGER
PDP page, Edit button triggered from product details, permission-aware
Editing lives where the data lives.